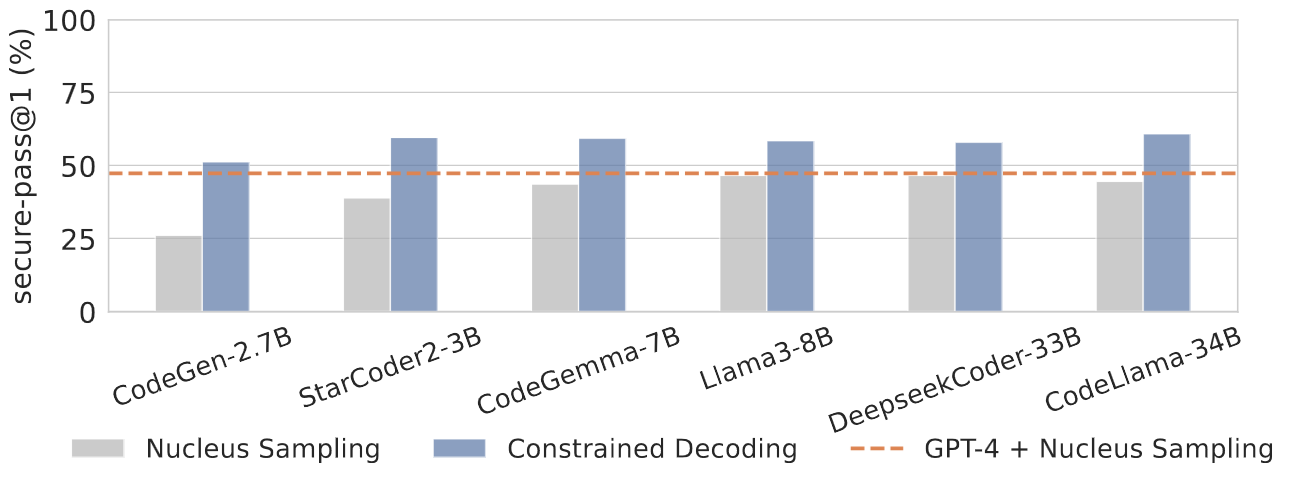
New Metrics
Previous works calculate the security rate as the percentage of secure programs within unique generated programs that can be parsed and compiled. This does not measure correctness and forgives generated code that is functionally wrong. This is disconnected from the standard pass@\(k\) metric widely used in the literature for comparing performance of Code LLMs, which defines the expected likelihood of generating any correct code output within \(k\) code outputs. Thus, we propose two new evaluation metrics: secure@\(k_{\text{pass}}\) and secure-pass@\(k\). When \(k = 1\), secure@\(1_{\text{pass}}\) measures the likelihood of any generated correct code being secure; secure-pass@1 measures the expected likelihood of generating both secure and semantically correct code given a single generation.
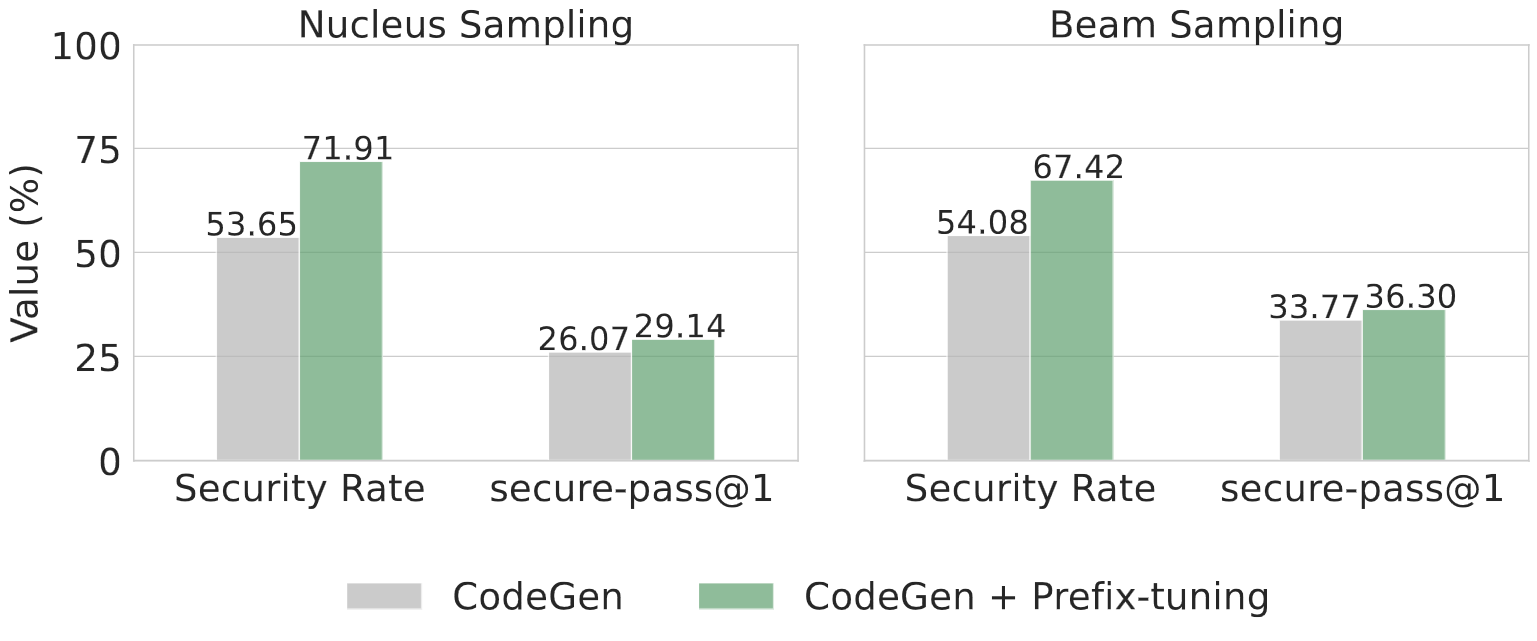
In the above figure, we compare CodeGen + Prefix-tuning model, trained with the SOTA defense SVEN, against the baseline CodeGen model. Our metric secure-pass@1 is more realistic than SVEN Security Rate. Since we evaluate both security and correctness of generated code, while SVEN Security Rate does not evaluate correctness. SVEN Security Rate severely overestimates how secure a model really is. The secure-pass@1 of CodeGen + Prefix-tuning is only 2.53% better than CodeGen with Beam Sampling.